Union-Find Set / Disjoint Set Union 并查集介绍
December 02, 2021
8153
开篇废话
数据结构「并查集」(Union-Find),也称「不相交集合」(Disjoin-Sets)挺火的,刷题的时候一直遇到,刷到必是medium以上。本身原理并不复杂,就是实现代码稍微多了点。
原理
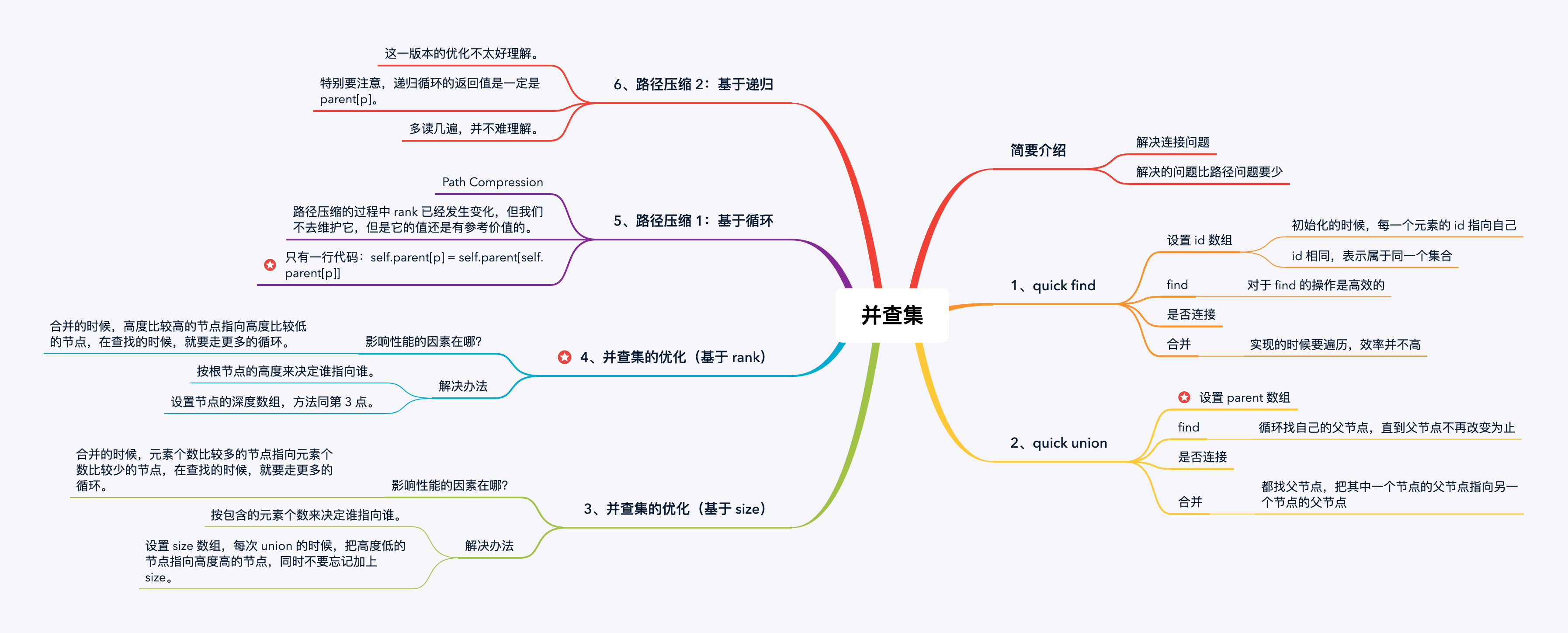 并查集主要知识点导图
并查集主要知识点导图
主要操作
并 Union
把两个集合合并成一个集合,表示这两个集合之间产生连接
查 Find
查询元素属于哪个集合
代码实现
代码框架
代码基本框架如下,对于find和union下面会介绍不同的实现
1 | |
Quick Find 实现
此实现重点在于超快速find方法,时间复杂度在O(1),而对于union时间复杂度是O(n)
1 | |
Quick Union 实现
此实现是最常用的版本,其他的优化也是基于此版本
虽然提高了find方法的时间复杂度,但平均了union的时间复杂度,总体效率会高于Quick Find方法
1 | |
按秩合并优化 实现
针对union操作的优化,在union操作时,根据约定的秩序从两个根节点中选择新的根结点
标准按秩,按当前树的高度合并
1 | |
人多势众,按当前集合元素数量合并
1 | |
路径压缩优化 实现
针对find操作的优化,在find操作时,压缩已查找的路径,具体实现有两种,差距不大
完全压缩(递归)
1 | |
隔代压缩(循环)
1 | |
终极优化 版本
注:这里存在个人偏见
路径压缩优化后是否还需要按秩合并存在一丢丢的争议,读者可自行斟酌
1 | |
复杂度
Time Complexity: O(Nα(N)) ≈ O(N), where N is the number of vertices (and also the number of edges) in the graph, and α(N) is the Inverse-Ackermann function. We make up to N queries of dsu.union, which takes (amortized) O(α(N)) time.
Space Complexity: O(N)
刷题
常用方法
- 通过一些方法将自定义类型转为整型后使用并查集(e.g. 生成哈希值;二维变一维)
- 使用链表 + 映射(Map)
- 使用桩,stub
My Favorite
- 1267. Count Servers that Communicate (这题特别好,开眼界了,除了基本的使用方法,点和点join之外,还可以自己和自己join)
- 947. Most Stones Removed with Same Row or Column (同理上一题)
基本
- 547. Number of Provinces (加岛屿计数器)
- 684. Redundant Connection (
unique二用) - 128. Longest Consecutive Sequence (+size数组)
- 261. Graph Valid Tree (+count)
- 323. Number of Connected Components in an Undirected Graph (+count)
- 695. Max Area of Island (+size数组)
- 737. Sentence Similarity II
- 839. Similar String Groups
- 990. Satisfiability of Equality Equations
- 1061. Lexicographically Smallest Equivalent String
- 1020. Number of Enclaves (+stub)
- 1101. The Earliest Moment When Everyone Become Friends
- 1258. Synonymous Sentences
- 1627. Graph Connectivity With Threshold
- 1361. Validate Binary Tree Nodes
- 1319. Number of Operations to Make Network Connected
- 1559. Detect Cycles in 2D Grid
- 1579. Remove Max Number of Edges to Keep Graph Fully Traversable
- 1905. Count Sub Islands
- LCS 03. 主题空间
- 1135. Connecting Cities With Minimum Cost
变体
- 200. Number of Islands (扁平化,降维,2D变1D)
- 130. Surrounded Regions (扁平化; 特殊占位)
- 721. Accounts Merge (Map?)
- 827. Making A Large Island
- 886. Possible Bipartition (Map? 算是一种变体吧?想解法还是想了一会儿的)
- 924. Minimize Malware Spread (难的是计算的部分,ufs本身还是很straightforward的)
- 928. Minimize Malware Spread II (上一题的变体)
- 1202. Smallest String With Swaps
- 1254. Number of Closed Islands (54SB, 很拙劣地做出了这道题,双%5,战五渣)
- 1584. Min Cost to Connect All Points
- 1631. Path With Minimum Effort
- 1722. Minimize Hamming Distance After Swap Operations
- 1970. Last Day Where You Can Still Cross
- 2076. Process Restricted Friend Requests (加一个restrictions map)
- 2092. Find All People With Secret (思考isolate)
魔鬼
- 305. Number of Islands II (corner cases折磨人:数组元素重复;land count有增有减)
- 399. Evaluate Division (数学题)
- 685. Redundant Connection II
- 952. Largest Component Size by Common Factor
- 959. Regions Cut By Slashes
偷看答案
- 785. Is Graph Bipartite?
- 803. Bricks Falling When Hit
- 1168. Optimize Water Distribution in a Village
- 1697. Checking Existence of Edge Length Limited Paths
- 1724. Checking Existence of Edge Length Limited Paths II
未解之谜
- 694. Number of Distinct Islands
- 711. Number of Distinct Islands II
- 765. Couples Holding Hands (我想不明白,玄学)
- 778. Swim in Rising Water
- 1102. Path With Maximum Minimum Value
- 1391. Check if There is a Valid Path in a Grid
- 1632. Rank Transform of a Matrix
- 1998. GCD Sort of an Array
- 2003. Smallest Missing Genetic Value in Each Subtree
最小生成树
- 1489. Find Critical and Pseudo-Critical Edges in Minimum Spanning Tree
- 1569. Number of Ways to Reorder Array to Get Same BST
参考
